NeurIPS 2021 — Curated papers — Part 1
UniDoc: Unified Pretraining Framework for Document Understanding
Authors has proposed a self-supervised framework for document understanding from multi-modal point of view. Language Pre-training using transformers have become extremely popular. In this work, authors have showed how to do SSL using transformers by taking inputs from different modalities such as image and text.
UniDoc has mainly 4 steps :
- Feature Extraction : Given a document image I and location of document elements, using OCR sentences and it’s corresponding bounding boxes are extracted.
- Feature Embedding : For bounding box, features are extracted through CNN backbone+RoIAlign and they are quantized using Gumble-softmax (similar to Wav2Vec2) and embedding for sentences are extracted from pre-trained hierarchical transformers.
- Gated cross attention : It’s one of the main ingredient of the work , where cross-modal interaction takes places between text and visual embedding through typical cross-attention mechanism. Now gating is used to combine the representation from both modalities . (Gating is nothing but a learned parameter alpha (between 0 and 1) which determines how embeddings are combined ).
- Objective function : There are mainly three parts which constitutes the objective function. a) Masked Sentence Modelling (Unlike words as in the case of BERT). b) Contrastive learning over masked ROI c) Vision-language alignment.

There are many interesting ablation study has been done in the paper such as using of CNN backbone and Pre-training strategies.
Link to the paper : https://openreview.net/pdf?id=UMcd6l1msUK
One of the key idea is multi-modal interaction via cross attention and combining them through gated learned parameter
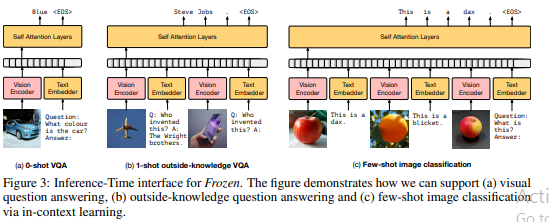
Multimodal Few-Shot Learning with Frozen Language Models
We all know how auto-regressive language models which are trained over billion parameters on large text corpus can perform well on most of the down-stream tasks with small dataset. Generally it’s ability is restricted to single modality, In this work authors has showed how it can work for multi-modalities such as vision and text .
- Freeze all the layers of language models
- Train a vision-encoder which takes image I and output of it’s pooling layer which has dimension of D * K channels , which are fed as sequence of k embeddings to pre-trained language transformer as a prefix embedding.
- Since transformer layers are frozen, gradients from transformer layer are only used to update vision encoder in an auto-regressive way.
- So Image and part of the caption is given as an output and label will be remaining part of the label.

Few of the examples of it’s performance on few shot learning is amazing
https://papers.nips.cc/paper/2021/file/01b7575c38dac42f3cfb7d500438b875-Paper.pdf
Idea is mapping the visual information to the text embedding space
Counterfactual Explanations Can Be Manipulated
Authors has explained about what are counter-factual explanations and how it can be manipulated by a following example:
ML has been used in the critical applications such as loan approval, if a person is denied a loan because of the decision from credit risk model. Now counter-factual explanations offers what minimum change needs to be done from input in order change the decision of credit risk model. How a little change in input can result in credit risk model’s decision as shown below.

As it can be seen in the image, a small delta change in the men’s Age input resulting in different explanation. This represents the disparity in the explanation between the groups (especially for protected groups).
In order to avoid these problems, they have come up with a adversarial training objective.
First, they find the desired perturbation Delta
Last term makes sure that perturbations aren’t big

Now, they introduce terms which depends on counter-factual algorithm A and fix Delta
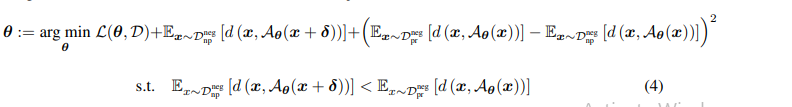
- Third term of the equation represents reducing the difference in counter-factual between protected and non-protected groups on original data
- Second term pushes the cost recourse for the non-protected group for perturbed input ,Referring to the above example, small change in the input of non-protected group (Men’ Age) should not result in different explanation hence that brings fairness towards protected group cost recourse.
https://papers.nips.cc/paper/2021/file/009c434cab57de48a31f6b669e7ba266-Paper.pdf
Idea is to make sure counter-factual explanations should be consistent between non-protected and protected groups


Comments
Post a Comment