DALL-E (Zero-Shot Text-to-Image Generation) -PART(2/2)
Link to my deep learning blogs : https://rakshithv-deeplearning.blogspot.com/
DALL-E consist of two components. First component is d-VAE(discrete-Variational Auto Encoder) and second is Auto-regressive transformer. First component is responsible for generating a tokens of size 1024 for an image of size 224x224. More details on this was covered in part-1 https://rakshithv-deeplearning.blogspot.com/2022/04/dall-e-zero-shot-text-to-image.html.
Transformer is decoder only network with 64 layers, each layer has 62 heads and model’s latent size is 64. Most of the ideas are borrowed from sparse attention paper which shows a way to reduce computation of a default self attention which is quadratic in time complexity (Link to the sparse transformer paper : https://arxiv.org/pdf/1904.10509.pdf ). There are three kind of attentions which are used in the transformer. Row attention, Column attention and causal convolution attention. From layer 1 to layer 63, we only have row or column attention. Causal convolution attention is used at layer 64 (final layer), author found this combination to be working well on Google’ conceptual caption dataset in earlier experiments. If layer (i-2) mod 4 equals to zero , column attention is used otherwise row attention is used.
Row attention :
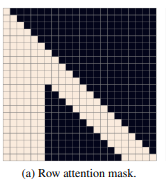
In this example, image token is 16 (originates from 4x4 image grid) and text token is 6.(This is just for illustration, in original paper image token is 1024 and image grid is 32x32 and text token is 256). In between text-tokens normal self-attention will be performed and every token of an image always attends an every token of text. But deviation is that, a particular token can only attends maximum of 5 previous tokens which mean if we imagine a 4x4 grid , image token at position 8 will attend its previous token from the same row such as 7,6,5 and 4 (which is of the same column).
Column attention

Extending the same example from row attention, When it comes to column attention each token will attend the token from the same column from previous rows. Example, token at position 16, will attend token from positions such as 12,8,4 and so on as shown in(b). In order to simply the implementation row and columns of image are transposed as shown in image c.
Convolutional attention mask:

As explained earlier Layer 1 to 63 composed of row and columns attentions. For example , for first 4 layer- row,column,row,row. Only at the last layer we have convolution based attention which attends to neighbouring tokens. Unfortunately, I’m not able to find much details about how exactly this has been computed.
Some of the other important details from the paper are :
- With respect to text tokens — a unique token is learned for padding at every position. Other option was to do something like -inf for such positions.
- There has been a lot of details regrading how to do mixed precision training using distributed strategy ( That probably requires a separate blog). To put it briefly, challenge is to fit 1 billion param in V100 16 GB GPU. They follow similar strategies such as activation checkpointing and modification of gradient scaling. They have provided guidelines to avoid numerical underflow.
- Instead of aggregating the gradients from different GPU by taking average, they have used PowerSGD(https://arxiv.org/pdf/1905.13727.pdf). Core idea is to solve communication bottleneck. Where gradient matric M (mxn)is approximated using P(mxr)multiplie by(Q(nxr).T)
- Dataset : 250M image-text pairs obtained from internet. Part of this dataset also includes Conceptual caption and YFCC 100M.
Link to the paper : https://arxiv.org/pdf/2102.12092.pdf


Comments
Post a Comment