Einsum equation:
It’ an elegant way to perform matrix or vector manipulation.
I find it’s extremely useful if I have to perform matrix multiplication of matrices which is of higher dimension, it gives a great flexibility to sum and multiply among certain axis.
Ex : if you have to multiply matrix A of shape (1,200,2,32) & matrix B of shape (2,32,32) and results in a matrix C of shape (1,200,32).
This can be implemented as follows:
np.einsum(‘abcd,cde->abe’,A,B)
That’s it !
It can be implemented similarly in Tensor-flow & PyTorch.
I was going through the keras implementation of Multi-head attention
In “Attention is all you need” paper, they concatenate different heads but in implementation they multiply different heads with weight matrix, I will be discussing few examples from this paper.
Syntax of “einsum” equation:
np.einsum(‘shape_of_A, shape_of_B -> shape_of_C’,A,B)
Let’s take a simple example:

Here, we are multiplying matrix A of shape (2,3) and matrix of shape (3,5) and results in matrix of shape(2,5).
A.shape[0] = a, A.shape[1] = b,
B.shape[0] = b, B.shape[1] = c
C.shape[0] = a, C.shape[1] = c
If we want to implement the same using loops:
- Output indices (indices after ‘->’) ‘ac’ forms the outer loop
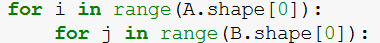
2. If an index is in both matrix and not in the output matrix then it will be summed across that index.
‘ab,bc’ -> ‘b’ is in both matrix and not in the output matrix so it will be summed (‘ab,bc->ac’)

Now, few more examples with respect to “Attention is all you need” paper. Let’s say our batch_size is 1, max_words is 200, it’s embedding is 32. Our input will be [1,200,32] and in order to obtain query, key & value, we can multiply with weight matrix let’s say we have 2 heads then[2,32,32] -> Wq . Similarly we will have Wk and Wv.
So [1,200,32] *[32,2,32] → [1,200,2,32]

After performing the attention we have matrix [1,200,2,32]. Now as per as paper, heads are concatenated but it’s actually multiplied as I mentioned earlier.
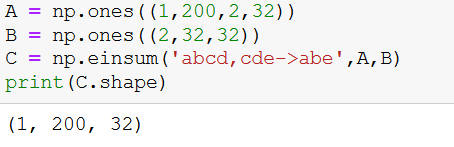
As shown earlier this can be written using loops as well
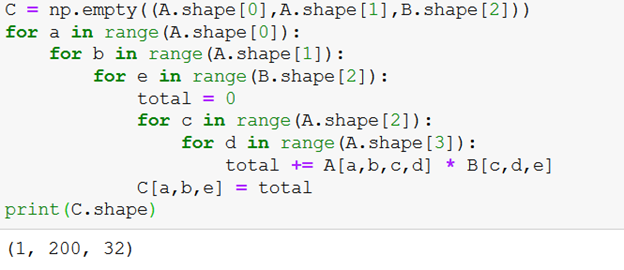
a,b& e forms the outer loop and we sum across (c&d) which are common in both and doesn’t appear in the output
Simple examples about transpose & row addition respectively





Comments
Post a Comment