Emerging Properties in Self-Supervised Vision Transformers (DINO)
Why:
It has information about semantic properties of image better than normal ViT , It achieves good accuracy on K-NN classifiers which means representations of different class are well separated for final classification
How:
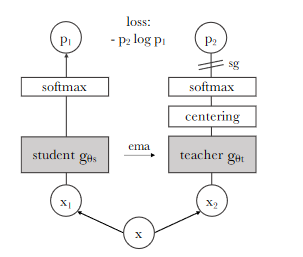
Similar to typical contrastive learning different augmented views passed through the 2 (student and teacher) network and then student network tries (learn) to match the probability distribution of teacher’s network
What:
It is called as DINO (self-distillation with no labels) instead of learning the difference between the representation here it’s about mapping the representation
TL: DR
1.Augmentation of images (multi-crop, Gaussian-blurr,etc)
2. All views will be passed through student network and only global view will be passed through teacher’s network
3. For given image , V different views can be generated (It will have at least 2 global views)
4.Student and Teacher network shares same architecture (ViT or ConvNet)
4. Output of network outputs k-dimension distribution which is passed through soft-max called as (s1,s2 (Student) & t1,t2 (teacher)) (Ex: if we only have 2 views)
5. Loss = CE(s1,t2 )+ CE(s2,t1), where CE -> Cross entropy (Ex: if we only have 2 views)

6. For student -> soft-max (Calculated using temperature parameter also called as sharpening ) i.e (s/tmp), where s-> output of the student’s network
7 . For Teacher → soft-max(sharpening & Centering)
Centering -> exponential moving avg , c=m*c+(1-m)*mean(t1,t2)
8. Hence for teacher, t=soft-max((t-c)/tmp), where t-> output of the teacher’s network
9. No gradient updates for teacher network it updates through student network via exponential moving average ,theta(t) = lambda * theta(t) +(1-lamba)*theta(s)
Points to Ponder:
1. What is the intuition behind distillation network in general?
2. What is the intuition for update strategy of teacher network?
3. Why it doesn’t work well without centering block in teacher’s network as mentioned in the paper?
link to the paper : https://arxiv.org/pdf/2104.14294.pdf



Comments
Post a Comment