An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Why:
Adaption of NLP’s famous transformer architecture for vision tasks and state of art has been achieved with relatively less computational resources compared to convolutions.
How:
Convert the image into sequence of patches and treat them as tokens like we do in NLP applications and feed the embedding of patch as in input to transformer and classification happens after a MLP head.
What:
It is called as vision transformer where how much attention needs to be given between patches is learned
TL: DR:
1. This has worked well for large dataset compared to moderate dataset because it doesn’t capture local properties(edges shared across 2 different patches and hence doesn’t generalize well)
2. Previous approaches tends to work on pixel level focusing on self-attention of a neighborhood or mixture of CNN+transformer.
3.Present work:
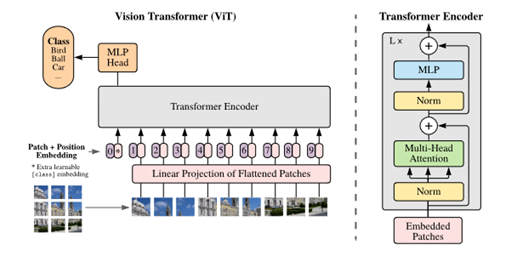
Points to ponder:
1. What if we change order in which we give the crops (one example : randomly changing the order or overlapping patches )
2. How to decide the each crop size (only from computation point of view?)
Link to the paper : https://arxiv.org/pdf/2010.11929.pdf



Comments
Post a Comment