MLP-Mixer: An all-MLP Architecture for Vision
Why:
Comparable results can be achieved for vision related tasks without using CNN or ViT (Self-attention) simply by using MLP
How:
Like Vision transformers image patches are fed as input tokens and it process through MLP’s
What:
This technique is called as MLP mixer , it has 2 kind of MLP’s , one which interacts with channels and other interacts with spatial region
TL: DR
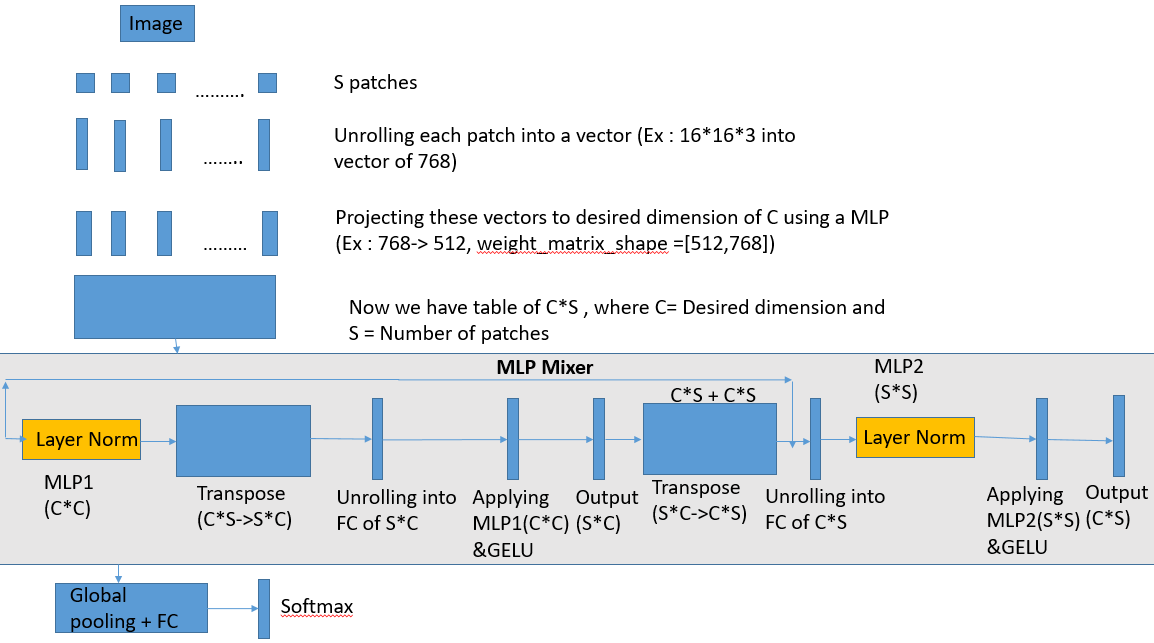
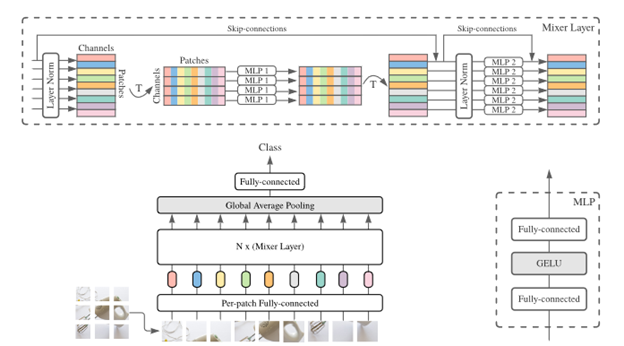
Architecture is self-explanatory, main idea here is we have 2 type of MLP layers ,
MLP1 deals with it’s channel component (Own Patch) and MLP2 interacts across spatial region (Other patches)
Points to Ponder:
1. Still property of parameter sharing isn’t used completely as much we do in CNN
2. Like vision transformers interesting to observe what happens if we change the order of patches or overlapping patch?
link to the paper : https://arxiv.org/pdf/2105.01601.pdf



Comments
Post a Comment